
TL;DR
The Julia LLM Leaderboard is a new benchmarking project that evaluates and compares the Julia code generation capabilities of various Large Language Models, revealing that, unsurprisingly, paid APIs like GPT-4 perform exceptionally well, but the locally-hosted models are quickly closing the gap.
Announcing the Julia LLM Leaderboard: A Benchmark for AI-Generated Julia Code
We're excited to announce the launch of the Julia LLM Leaderboard, a comprehensive benchmark project dedicated to evaluating the Julia language generation capabilities of various Large Language Models (LLMs). This unique repository is designed with a focus on practicality, simplicity, and the Julia community's needs.
The project presents a comparative analysis across multiple AI models, assessing their proficiency in generating syntactically correct Julia code. Our evaluation methodology includes simple and practical criteria like parsing, execution without errors of provided examples and passing unit tests. Each model can score up to 100 points based on these criteria, providing a clear and standardized measure of their capabilities.
Paid APIs
Initial findings reveal that paid APIs like GPT-4 and the MistralAI models show impressive performance, with "GPT-4-Turbo-1106" consistently ranking among the highest.
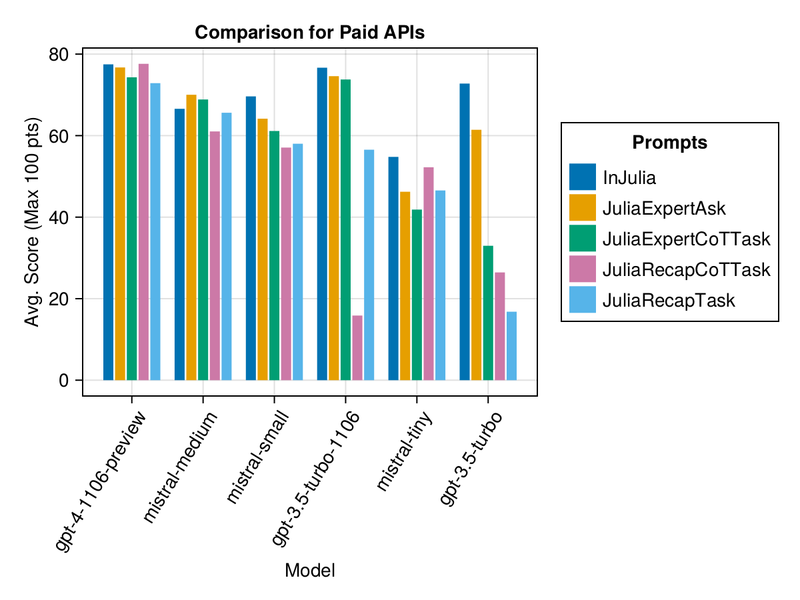
However, if you need a quick response and high-quality outputs, your best choice is "gpt-3.5-turbo-1106" (The "1106" version is important! The default GPT 3.5 Turbo ranks much lower)
For more plots and a table summary, visit Results for Paid APIs.
Locally-Hosted Models
Open-source models, though not as robust as the best-paid APIs, are rapidly catching up, with some like Magicoder, Phind CodeLlama, and DeepSeek showing notable results. My personal pick would be "magicoder:7b-s-cl-q6_K" served via Ollama.ai, because it has 7 billion parameters, so it's quite fast and the performance is solid.
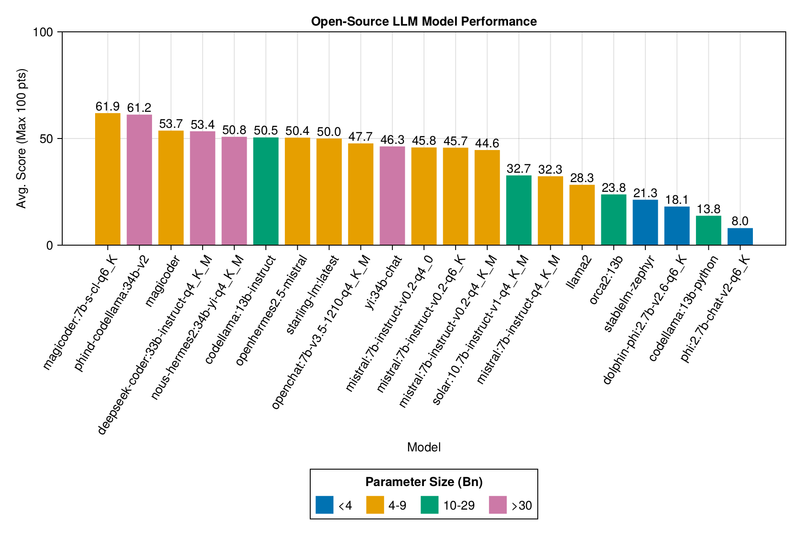
See more detail here.
Prompts, prompts, prompts
Moreover, the benchmark addresses the effectiveness of different prompting strategies. It turns out that even simple prompts can be quite effective, and larger prompts may sometimes confuse smaller models.
We used prompting templates available in PromptingTools.jl 0.6.0., except for "AsIs", which represented the raw task without any mention of Julia language (to see if the LLMs can infer it from the context).
| Prompt Template | Elapsed (s, average) | Elapsed (s, median) | Avg. Score (Max 100 pts) | Median Score (Max 100 pts) |
|---|---|---|---|---|
| InJulia | 16.7 | 11.7 | 50.6 | 50.0 |
| JuliaExpertAsk | 11.8 | 7.8 | 47.6 | 50.0 |
| JuliaRecapTask | 20.9 | 15.9 | 45.6 | 50.0 |
| JuliaExpertCoTTask | 19.7 | 14.9 | 43.9 | 50.0 |
| JuliaRecapCoTTask | 19.7 | 15.2 | 42.5 | 50.0 |
| AsIs | 36.3 | 11.2 | 13.0 | 0.0 |
Main takeaways:
- Always make sure to explicitly mention that you want Julia code (the case-in-point is the "AsIs" prompt which performed poorly)
- Just appending "In Julia, ..." can be enough to get a good trade-off of speed and performance
- In many cases, "JuliaExpertAsk" was quite successful. It doesn't hurt to stroke AI's ego :)
See more here.
Conclusion
These insights are just the tip of the iceberg. The full repository includes detailed documentation of the methodology and results. We invite the Julia community and AI enthusiasts to dive into the Julia LLM Leaderboard, contribute test cases, and explore the fascinating world of AI-generated code.
Stay tuned for more in-depth analysis and findings from this project!
PS: If you're curious about test cases or want to add a few more, see Results by Test Case and Test Definition.
Credit for the title image goes to DALL-E 3.

Top comments (2)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.