
TL;DR
The new RAGTools module in the PromptingTools.jl package introduces enhanced modularity and straightforward extension capabilities, enabling developers and researchers to easily customize and build Retrieval-Augmented Generation (RAG) systems tailored to their specific needs in Julia.
Introduction
The introduction of Retrieval-Augmented Generation (RAG) systems addresses key challenges in generative AI, notably the tendency to lack crucial information and produce hallucinated content. By integrating external knowledge, RAG systems significantly enhance the accuracy and reliability of AI-generated responses.
The RAGTools module within the PromptingTools.jl package enables the creation of such systems, offering a path to mitigate these issues. As this module matures, plans are in place to transition it into its own dedicated package, further facilitating the development and adoption of RAG systems.
RAGTools Module: A Primer
RAGTools offers an experimental but formidable suite of utilities designed to facilitate the crafting of RAG applications with minimal fuss. Central to its arsenal is the airag function, a master orchestrator that seamlessly combines AI insights with user-curated knowledge, unlocking new dimensions of accuracy and relevance in answers.
You can get started very quickly:
# required dependencies to load the necessary extensions
using LinearAlgebra, SparseArrays
using PromptingTools
using PromptingTools.Experimental.RAGTools
# to access unexported functionality
const RT = PromptingTools.Experimental.RAGTools
## Sample data
sentences = [
"Search for the latest advancements in quantum computing using Julia language.",
"How to implement machine learning algorithms in Julia with examples.",
"Looking for performance comparison between Julia, Python, and R for data analysis.",
"Find Julia language tutorials focusing on high-performance scientific computing.",
"Search for the top Julia language packages for data visualization and their documentation.",
"How to set up a Julia development environment on Windows 10.",
"Discover the best practices for parallel computing in Julia.",
"Search for case studies of large-scale data processing using Julia.",
"Find comprehensive resources for mastering metaprogramming in Julia.",
"Looking for articles on the advantages of using Julia for statistical modeling.",
"How to contribute to the Julia open-source community: A step-by-step guide.",
"Find the comparison of numerical accuracy between Julia and MATLAB.",
"Looking for the latest Julia language updates and their impact on AI research.",
"How to efficiently handle big data with Julia: Techniques and libraries.",
"Discover how Julia integrates with other programming languages and tools.",
"Search for Julia-based frameworks for developing web applications.",
"Find tutorials on creating interactive dashboards with Julia.",
"How to use Julia for natural language processing and text analysis.",
"Discover the role of Julia in the future of computational finance and econometrics."
]
sources = map(i -> "Doc$i", 1:length(sentences))
## Build the index
index = build_index(sentences; chunker_kwargs=(; sources))
## Generate an answer
question = "What are the best practices for parallel computing in Julia?"
msg = airag(index; question) # short for airag(RAGConfig(), index; question)
## Output:
## [ Info: Done with RAG. Total cost: \$0.0
## AIMessage("Some best practices for parallel computing in Julia include us...
Unveiling New Functionalities
The latest update to the RAGTools module introduces key features that enhance the creation and analysis of RAG systems:
Modular Interface: The RAG pipeline is now broken down into distinct components (see details below), allowing users to customize and extend each phase with ease. Simply define a new type and method for only the components you wish to modify.
Pipeline Transparency: Users can now view detailed background information on the RAG pipeline, including the sources selected and the process at each stage (use
return_all=true).Advanced RAG Functionality: Default pipeline configuration now comes with question rephrasing, reranking results, and two-step answer refinement. There is even a
postprocessplaceholder, so you can add some logging or other transformations. You can easily switch between different implementations thanks to Julia's method dispatch while calling the same top-level function.Answer Annotation: The final answers can be annotated with hallucination scores, showing the overlap with source materials and indicating the origin of specific information within the answer.
Answer Annotation Example
With a small change, you can see which sources were used for each sentence in the answer ([1]), how strongly they were supported ([..,0.9]), and the color highlight of the "unknown" words (with magenta color):
result = airag(index; question, return_all = true)
pprint(result)
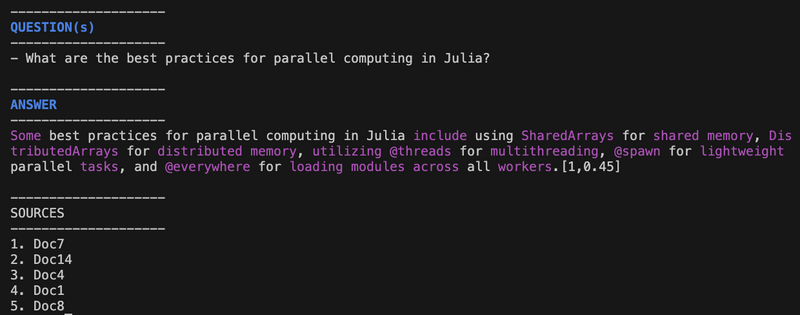
You immediately see that while a lot of the package names and macros look sensible, they did NOT come from our trusted knowledge base (all highlighted in magenta). In real life, we would also have clearly labelled source links that we could verify with one click.
The annotation system is fully customizable (bring your own logic, styles, etc.).
You can also obtain this information in HTML format to easily show it in your Genie apps!
A Closer Look at the Modular Interface
At the heart of the new RAGTools interface is its modular design, encouraging the interchange of pipeline components. This approach allows for extensive customization at every stage, from data preparation to answer generation, ensuring that developers can easily adapt the system to meet their specific needs.
This system is designed for information retrieval and response generation, structured in three main phases:
-
Preparation, when you create an instance of
AbstractIndex -
Retrieval, when you surface the top most relevant chunks/items in the index and return
AbstractRAGResult, which contains the references to the chunks (AbstractCandidateChunks) -
Generation, when you generate an answer based on the context built from the retrieved chunks, return either
AIMessageorAbstractRAGResult
The associated methods are:
-
build_index: Indexes relevant documents for retrieval. -
retrieve: Selects pertinent information chunks based on the query. -
generate!: Produces the final answer using the retrieved data.
airag is simply a wrapper around retrieve and generate!, providing a convenient way to execute the entire RAG pipeline in one go.
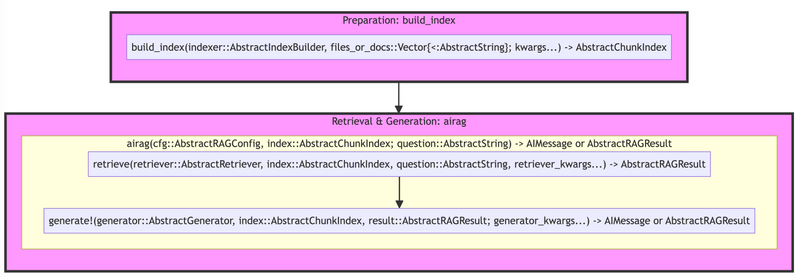
Note that the first argument is always the main dispatching parameter that you can use to customize the behavior of the pipeline. This design ensures that users can easily swap out components or extend the system without disrupting the overall functionality.
RAG Pipeline Workflow
The RAG pipeline is structured into distinct stages, each comprising several critical sub-steps to ensure the generation of accurate and relevant answers.
If you want to change the behavior of any step, you can define a new type and method for that step.
All customization are subtypes of the abstract types, so use subtypes function to discover the currently available implementations, eg, subtypes(AbstractReranker).
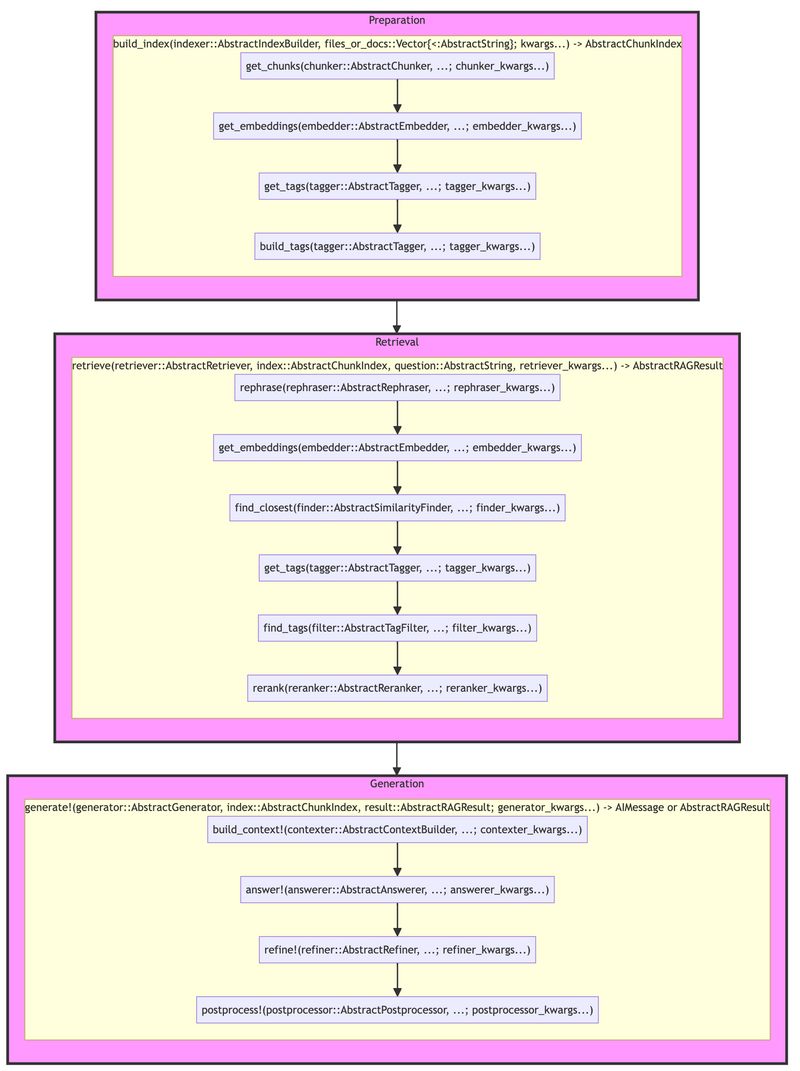
Preparation Phase
-
build_index:-
get_chunks: Segments documents into manageable chunks. -
get_embeddings: Generates embeddings for similarity searches. -
get_tags: Tags chunks for efficient filtering.
-
Retrieval Phase
-
retrieve:-
rephrase: Optionally rephrases queries for better matching. -
find_closest: Identifies the most relevant document chunks. -
find_tags: Filters chunks based on specific tags. -
rerank: Reranks chunks to prioritize the best matches.
-
Generation Phase
-
generate!:-
build_context!: Constructs the context from selected chunks for the answer. -
answer!: Generates a preliminary answer. -
refine!: Refines the answer for clarity and relevance. -
postprocess!: Applies final touches to prepare the response.
-
A visual summary with the corresponding types:
Where to Start: Quick, Experiment, or Customize
To operate the RAG system:
-
Quick Start: Utilize
airagfor an immediate, out-of-the-box solution, suitable for rapid testing. -
Experimentation: Leverage
RAGConfigto try out different implementations ofairag, tweaking the system for better performance. -
Customization: Dive into
retrieveandgenerate!for detailed customization, tailoring the process to your precise requirements.
How to Customize the Pipeline
If you want to customize the behavior of any step, you can do so by defining a new type and defining a new method for the step you're changing, eg, introduce a new reranker:
PromptingTools.Experimental.RAGTools: rerank
struct MyReranker <: AbstractReranker end
rerank(::MyReranker, index, candidates) = ...
And then you would set the retrive step to use your custom MyReranker via reranker keyword argument, eg, retrieve(....; reranker = MyReranker()) (or customize the top-level dispatching AbstractRetriever struct).
Passing Keyword Arguments to Customize the Pipeline
When you need to adjust specific aspects of the RAG pipeline, keyword arguments (kwargs) allow for targeted modifications. This approach is especially useful for customizing individual components within the system.
To pinpoint the right keyword arguments (kwargs) for customization:
- Consult the Diagram: Review the RAG pipeline diagram or documentation. Identify the component you want to adjust.
-
Use the Format: Apply
<dispatch_type>+_kwargsfor direct customizations. For nested adjustments, use prefixes that reflect the hierarchy (e.g.,retriever_kwargs -> rephraser_kwargs -> template).
This approach allows for precise tweaks at any level of the pipeline, ensuring your modifications target exactly what you need.
Practically, for a broad configuration, you might start with a RAGConfig instance, specifying components like the AdvancedRetriever to enhance retrieval capabilities. Preparing kwargs in advance facilitates managing the intricacies of nested configurations:
cfg = RAGConfig(; retriever=AdvancedRetriever())
# Organize kwargs for clarity and manageability
kwargs = (
retriever=AdvancedRetriever(),
retriever_kwargs=(
top_k=100,
top_n=5,
rephraser_kwargs=(
template=:RAGQueryHyDE,
model="custom-model"
)
),
generator_kwargs=(
answerer_kwargs=(
model="custom-answer-model"
)
),
api_kwargs=(
url="http://localhost:8080"
)
)
# Execute with prepared arguments
result = airag(cfg, index, question; kwargs...)
In scenarios where direct interaction with components like the retriever is needed, configure its kwargs similarly:
retriever_kwargs = (
top_k=100,
top_n=5,
rephraser_kwargs=(
template=:RAGQueryHyDE,
model="custom-model"
),
api_kwargs=(
url="http://localhost:8080"
)
)
# Apply to the retriever function directly
result = retrieve(AdvancedRetriever(), index, question; retriever_kwargs...)
Delving deeper into the pipeline, for tasks such as rephrasing, specific kwargs can be directly applied to fine-tune the operation:
rephrase_kwargs = (
model="custom-model",
template=:RAGQueryHyDE,
api_kwargs=(
url="http://localhost:8080"
)
)
# Customize the rephrase step
rephrased_query = rephrase(SimpleRephraser(), question; rephrase_kwargs...)
This structured approach to passing kwargs ensures that each stage of the RAG pipeline can be precisely controlled and customized, allowing for a tailored question-answering system that meets specific needs.
Using Custom Indexes or Vector Databases
RAGTools default implementation is built with an in-memory index suitable for datasets up to 100,000 chunks. For larger datasets or specific indexing needs:
Define a Custom Index: Create a new index by extending
AbstractChunkIndex. Use theChunkIndexas a guide for required fields.Customize Interaction Methods: Implement new methods for your index to integrate with the retrieval process of the RAG pipeline.
Share Your Implementation: Contributions of integrations with common vector databases are welcome. They enrich the community's resources, enabling more versatile RAG applications.
You would use the same approach to build a hybrid index (semantic search + BM25).
This approach allows RAGTools to accommodate a broader range of applications, from large-scale datasets to specialized indexing strategies, enhancing its utility and adaptability.
Conclusion
The latest enhancements in the RAGTools module are a leap forward in democratizing the development of RAG systems. By blending ease of use with deep customizability, we open new avenues for developers and researchers to explore AI-driven question-answering possibilities.
We Want to Hear from You!
Your feedback and use cases are crucial as we refine RAGTools and prepare to carve it out into its own package. Whether you're exploring the vanilla implementation or integrating vector databases, share your insights with us. Your contributions are key to enhancing this interface, making it more robust and versatile for the community. Help shape the future of RAGTools—join us in this exciting journey towards a more powerful and user-friendly generative AI toolkit.
Credit for the title image goes to DALL-E 3.

Top comments (0)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.