
TL;DR
Explore the new capabilities of LLMTextAnalysis.jl to explore any arbitrary concept and spectrum. We demonstrate how to easily evaluate responses on whether they are "action-oriented" and "forward-looking".
Introduction
In the world of data science, Large Language Models (LLMs) offer an innovative approach to text analysis. This blog post demonstrates an application of LLMTextAnalysis.jl on the City of Austin's Community Survey, focusing on classifying responses by their alignment with specific concepts and spectrums.
We will pick one open-ended question. Let's say we want to help the mayor to prioritize ideas,
so we will lay out the verbatims against the concepts of being "action-oriented" and "forward-looking".
Getting Started
using Downloads, CSV, DataFrames
using Plots
using LLMTextAnalysis
plotlyjs(); # for interactive plots
Preparing the Data
Download the survey data
Downloads.download("https://data.austintexas.gov/api/views/s2py-ceb7/rows.csv?accessType=DOWNLOAD",
joinpath(@__DIR__, "cityofaustin.csv"));
Read the survey data into a DataFrame
df = CSV.read(joinpath(@__DIR__, "cityofaustin.csv"), DataFrame);
Let's select one of the open-ended questions, eg,
col = "Q25 - If there was one thing you could share with the Mayor regarding the City of Austin (any comment, suggestion, etc.), what would it be?"
docs = df[!, col] |> skipmissing |> collect;
Building the Text Index
Indexing documents, or survey responses in our case, is the first critical step. The build_index function prepares the data for subsequent analysis.
index = build_index(docs)
# Output: DocIndex(Documents: 2933, PlotData: None, Topic Levels: None)
Let's use those 30 seconds to understand the difference between a concept and a spectrum.
Understanding Concept and Spectrum
Sometimes you know what you're looking for, but it's hard to define the exact keywords. For example, you might want to identify documents that are "action-oriented" or "pessimistic" or "forward-looking".
For these situations, LLMTextAnalysis offers two basic functionalities: train_concept and train_spectrum. Each serves a different purpose in text analysis.
-
Concept (type:
TrainedConcept):- Purpose: Analyzes a single, specific idea within texts.
- Ideal Use: Best for targeted analysis focusing on a singular concept.
-
Function:
train_concept
-
Spectrum (type:
TrainedSpectrum):- Purpose: Places texts on a continuum between two opposing concepts.
- Ideal Use: Suitable for comparative analysis between contrasting ideas.
-
Function:
train_spectrum
Why do we need train_spectrum and not simply use two TrainedConcepts? It's because the opposite of "forward-looking" can be many things, eg, "short-sighted", "dwelling in the past", or simply "not-forward looking".
Training a Concept
Let's say we want to identify documents that are "action-oriented".
We can use train_concept to train a model to identify documents that are "action-oriented" and score the documents against the concept.
Let's show the top 5 documents that are most "action-oriented".
concept = train_concept(index,
"action-oriented";
aigenerate_kwargs = (; model = "gpt3t"))
scores = score(index, concept)
index.docs[first(sortperm(scores, rev = true), 5)]
5-element Vector{String}:
"stop delaying important decisions and make the best one available and move on to solutions"
"We need real transportation options, not just more lip service and endless studies that do not achieve implementation."
"We need a comprehensive plan/vision for managing the growth of this city!"
"Ensure that all citizens, regardless of race/ethnicity, gender, gender identity feel protected and respected by our police services."
"we need to plan for global climate change, water and energy programs must be robust"
Training a Spectrum
We may want to define an arbitrary "spectrum" (axis/polar opposites) and score documents on it.
Let's introduce a spectrum for "dwelling in the past" vs "forward-looking".
The higher the score (eg, 100%), the more "forward-looking" the document/text is.
Let's show the top 5 documents that are most "forward-looking".
spectrum = train_spectrum(index,
("dwelling in the past", "forward-looking");
aigenerate_kwargs = (; model = "gpt3t"))
scores = score(index, spectrum)
index.docs[first(sortperm(scores, rev = true), 5)]
5-element Vector{String}:
"Enhance affordability and ensure a diverse, healthy population."
"MANAGING GROWTH IN A WAY THAT IMPROVES QUALITY OF LIFE FOR ALL CITIZENS"
"Affordable housing. Better planning for future. Mass transit (rail system that covers City wide."
"Plan for greater urban density and more public transportation."
"need more affordable housing and more public transportation to ensure diverse and successful population"
And how about the ones "dwelling in the past" (set rev=false to look for low scores)?
index.docs[first(sortperm(scores, rev = false), 5)]
5-element Vector{String}:
"It is so sad to see long time local business disappearing. We loved Austin because it was unique, and used to have the feeling of a small town with the advantages of a big city. Now, it is just another city in Texas with gas stations, banks and Walgreen's on every corner of every rd. So sad to see Austin go down that rd!"
"The cost of living in Austin and the surrounding v areas is 100% absurd. Beyond ridiculous. I would do anything to have the \"old Austin\" back."
"Used to be proud of Austin and tour visiting friends around.\nNow it's just a crowded nasty city."
"I WISH I HAD BUS STOP BACK AT LEDESMA AND LOTT. I USED TO RIDE THE BUS TO WORK."
"I'm really sad about what Austin has become. It used to feel like home. Now, it just feels like a big, impersonal city with not much personality, and a lot of traffic (and high taxes). The city that I loved is gone, which makes me sad and angry."
Visualization and Interactive Analysis
Visualizing the results is made easy with plot and can be enhanced with PlotlyJS for interactivity.
The positions of arguments concept and spectrum are important, as they determine the position of the concepts in the plot (x-axis, y-axis)
pl = plot(index, spectrum, concept;
title = "Prioritizing Action-Oriented and Forward-Looking Ideas (Top-right Corner)")
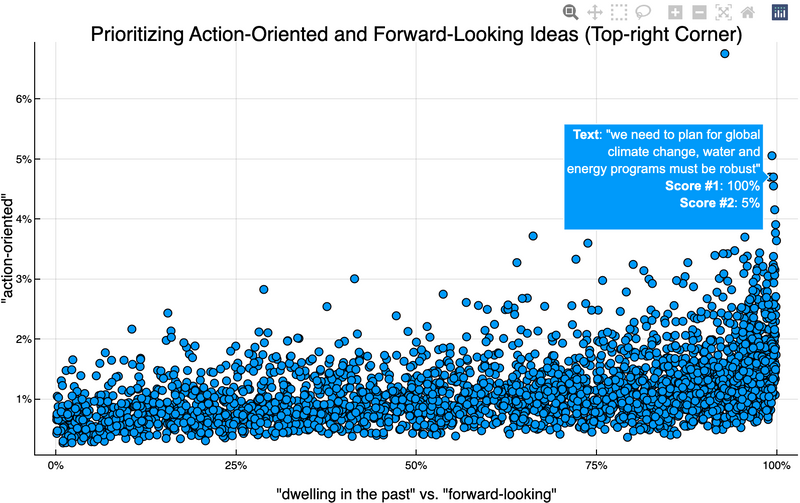
Note: What if you need to add some additional information to the tooltip for each data point? You can do that with hoverdata argument, see ?plot for more details.
Conclusion
Concept labeling provides a nuanced approach to text analysis, suitable for a wide range of applications in data science. It empowers users to go beyond traditional analysis methods, offering insights into previously unexplored areas of textual data.
Credit for the title image goes to DALL-E 3.

Top comments (0)