
Recently, I read a lot of materials about Bayesian Statistics. Same with other programmers , lots of perplex, such as what are difference about Classical Statistics(CS) with Bayesian Statistics(BS),how to use BS ? etc.
We must understanding
Bayes Theorembefore we use BS?
It depdends
For most of Programmers, actually we talk about
probability programming language, not BS. With some Programming Framework, likeTuring.jl, we don't need understandingBayes Theoremat all. We Just need to understandBayes Workflow, like us use application on iPhone, but we don't need understanding how A15 cpu working principle. We are learning how to use Bayesian Application, not Bayesian's CPU.For Bayesian expert Programmers, understanding
Bayes Theoremnot enough, they must use many many other techniques.
Most importantly, our human's cognition processing flow extremely likely with Bayesian Workflow.
In this blog, I will describe some learning points about probability programming with BS
In my experience, I want you keep thinking two problems:Where data came from ? What is Data Source'params, until you understanding what I talking about.
the meaning of
likely hoodwhy In
Truing.jl's model code using Greek alphabet
Where data came from?
Mocking Data
If we want to develop E-Business website. First we need some data, we can use some mocking package or website to produce data
Such as https://mockaroo.com
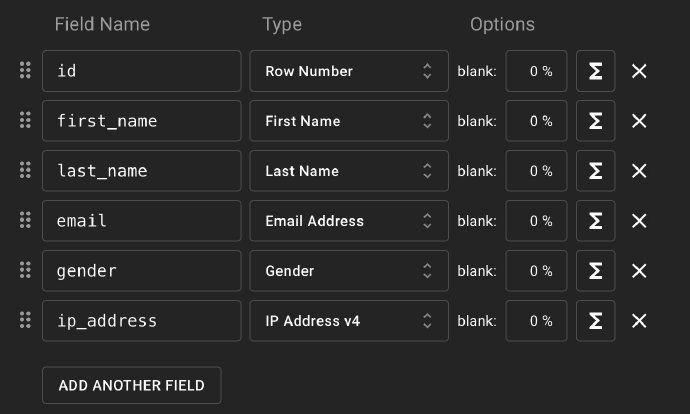
We need some Fields defining structure of mocking data. All data follow fields definition. Once we defined all fields correctly, we get a data producing machine.
These Fields can be called params of data source
Then, we program some CRUD code to manipulate data. For example, we read 100 rows of data. that is not over, we need check results.If we get wrong result, maybe data structure has problem, maybe code has problem. So we need modify somewhere. Iterate several times until most results correctly.
In this section , we build a workflow starting from data source.
If we have an experienced programmer to design data structure, workflow can be less error and spending less time.This can be thought as prior condition. If you ever learned some BS, you will recognize some things.
Remember, if data has meaning , data structure of data source has meaning. In BS we try to find these data source's params!
Real data producing machine
I like running , my application record many data of running.
So I'm a data producing source. What is Fields(params) of source ? How to explain these data?
You are not familiar with me , let talk Usain Bolt

Bolt is a crazy running data producing machine, I'm just a mediocre running data producing machine
We are both human , we are same machine type.
But we have different Fields(params), that' why we get different running data .
similarly params produce similarly data

For these guys, collect some data , you can't tell which data producing by Bolt.
Usually, we collect data from a time slice(instant time), assuming machine's param keep constant.
In single time, maybe we find a beautiful view in joggling , so we take pictures, this make running record getting worse.
This change not cause by params's change , just environment factors. environment factors are uncountable.
In long time range , some params changed , such as after long time training , you get better record than ever. During aging , you running speed get slowly.
So what's point above examples?
In CS, we focus on data and computing. In BS, we care about data source, data source's params and data.
In CS we test params. In BS we estimate params
CS seems like a block of BS workflow.
probability distributions has different use in CS and BS
In CS, if we have real data, we don't need probability distributions , some CS methods need to check distributions, but not use distributions. If we have no data, we can use probability density function (pdf) to mock data, that's all.
Like we buy goods, but we have not rights to modify machine's params.
In BS, probability Distributions is vital building block, we need goods, also need making machine by ourselves.
We can change machine's params to make them producing better goods.
If we choose semi-finished products, we can speed getting our goods. (That is prior condition)
Mocking data in not a part of CS, neither BS.
What is data producing machine's shape?
Most of time when we learning math, we start from an expression . But most of time nature model has no expression at all.
In Calculus , we use series to approximate a function
In Algebra, we use function of linear combination to get approximate function expression.
We don't care about what is function expression, we just care about expression's outputs.
This method like Duck type
If it looks like a duck and quacks like a duck, it’s a duck”
likely hood
This is likelyhood, and in Turing.jl, we use ~, not =. That's why, cause we approximately get a set of data's data source's params.
That is the likelyhood meaning. If a distribution with these likelyhood params produce our observation data, job done!.
here is workflow:
- Get
semi-finished machine - By data, to tuning machine's params
- Check whether machine to produce our data.
- Not work , return to 2.
- work great, return a
likelyhoodmachine
If not work at all , we need choose another semi-finished machine repeat procedure
Why Turing's model using Greek alphabet?
In Statistics, Population and Samples are most important concept. Population's params represent by Greek alphabet
Usually, we sampling some entity from Population,then collect ing sample's data .
You can see Population is data source. In BS, we estimate data source's params, that is Population's params. that is why in Turing.jl's model using Greek alphabet.
That is called Parametric estimate.
On the other hand, in CS,
It is Parametric tests, in CS, params doesn't change.
conclusion
Here is a very short introduction to Bayesian work flow.
As for you, it is a semi-finished lesson, you need repeat and repeat before you get finished lesson. Need more bayesian data, modify lesson params.
For me it is a semi-finished blog, I need many iteration to make it better.
That's all . I'm not good at English, please correct and modify my params!

Top comments (1)
Add to the discussion