
Introduction
When I started in the world of Machine Learning, I used other programming languages throughout my learning process and also my professional development. Julia was introduced to me when I was searching for bleeding edge technologies that could be the field's future and contribute to the state of the art. In a short time, this programming language became my first line source of learning and the project I wanted to see it being applied across my country (Peru). So with hands on, I started practicing to implement some old projects but using the awesome features coming from Julia. But that wasn't enough; I knew about Google Summer of Code since I was in my college second year and I always wanted to be part of the program but I didn't considered myself as "eligible" (my imposter syndrome). Well, that was until this year that I decided to apply to an interesting project that I was using: MLJ.
Unravelling the depths
Choosing the project
When I started planning getting into the program, I didn't know exactly which project I will work on. I sent some emails to Anthony Blaom, the lead contributor of MLJ and also my mentor; showing my interest about participating in the program and also be a project contributor. He always answered all my concerns, and sent me a list of projects that I could take. My interest was divided by two projects: a survival analysis model implementation and a MLOps platform integration. My not advanced experience with statistics made me decide to work in the project related with MLFlow, a well-known machine learning model tracking platform. After Anthony suggestion, I sent some emails to the other mentor behind this project, Deyan Dyankov, to delve into the details of MLFlow.
The project
MLJ didn't have a way to log the most important workflow information in a simpler way, just like other programming languages that have special libraries to work with tracking platforms. The main goal was to adapt the MLJ components behind the training process to log all the required information. To achieve this objective, my mentors prepared me to understand the functionality behind each project that will allow the development of our interface: MLJBase, MLJModelInterface, and MLFlowClient.
Making MLFlowClient up to date
Deyan mentioned that MLFlowClient was ensured to work with versions 1.21.0 and 1.22.0 of mlflow. However, some endpoints from the REST API changed their responses over time and this broke certain core functionalities.
My first step in this project was about converting the server timestamps to UTC time. This error was particular because it was not completely related to the library, but with mlflow internal functionality (the UI platform is showing the client side time). It was good to know that with this change Deyan considered my GSoC application and sent a email to Anthony to continue with the selection process.
A lot of work was done implementing new features coming from new versions of mlflow, but I consider that the most important change in this phase was the complete project refactoring. This update changed the entire project architecture structure and improved the test suite in a way that new developers can start collaborating with the project easily.
After that, I revisited this project just to implement utilities that will be used by other projects (like the health check).
Different approaches with MLJBase
Just after finishing with MLFlowClient, I continued learning about MLJBase: the core package behind the entire MLJ ecosystem. Anthony helped me a lot to understand the deep functionality behind everything on this project. I'm completely thankful about his patience, because some concepts were completely new for me (like multiple dispatch).
The package extensions approach
Our first approach was to implement all the changes related to integrating MLFlowClient using package extensions. This bleeding edge feature was introduced in Julia 1.9, inheriting the functionality implemented by a package named Requires. In simple terms, this allows us to include external dependencies without including them... that sounds weird, right? Well, it's very simple.
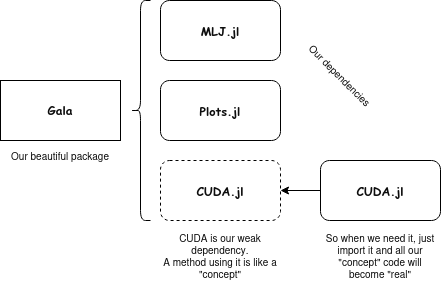
Figure 1: A package extensions example
With this approach, we can define functions that use heavy dependencies without including them when we first instantiate the project, incrementing the importing speed a lot!
However, even if it seems like a great way to implement the project, MLFlowClient wasn't the heavy project that will make MLJ slower, and also we disagreed with the idea that the user will need always to import that library. So was it completely necessarily? I don't think so.
An interface: a classical approach
After our concerns, Anthony suggested to create a new package that joins all the MLJ components and MLFlowClient... what a great idea! This allowed different things that package extensions make difficult:
- A clean and classical way to implement things
- Removing the extra step of importing the package to the user (enhancing user experience!)
- Sharing utilities across the extended functions (avoiding duplication)
We started to design how this is going to work, documenting our ideas and taking a weekly meeting to discuss about the next project steps.
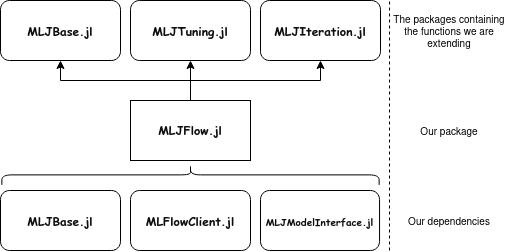
Figure 2: The project design (well, until now)
With this in mind, the first task was moving the entire implementation made in the previous approach to the new package. This included changes in MLJBase.jl and MLJModelInterface.jl to allow our new logger type to be passed throughout the MLJ workflow. Next, we polished that code to met the project requirements, and improving it.
The project
MLJFlow is a package that extends the MLJ capabilities to use MLFlow as a backend for model tracking and experiment management. Other programming languages have official API implementation, but Julia don't. This project helps it to achieve that. An example with a simple workflow is shown below:
using MLJ
# Instancing the logger
logger = MLFlowLogger(
"http://127.0.0.1:5000";
experiment_name="MLJFlow test",
artifact_location="./mlj-test"
)
# Get the data and choose our favorite model
X, y = make_moons(100) # a table and a vector with 100 rows
DecisionTreeClassifier = @load DecisionTreeClassifier pkg=DecisionTree
model = DecisionTreeClassifier(max_depth=4)
# Train it!
evaluate(model, X, y,
resampling=CV(nfolds=5),
measures=[LogLoss(), Accuracy()],
logger=logger
)
The information must be logged in a new run in your MLFlow instance under the MLJFlow test experiment name. You didn't need to define anything. That's awesome!
You can see more detailed information in this readme file.
What is left to do?
The project is perfectly working with singular models and composite ones. These contain simple non-special implementations in the functions that our project is using. However, the next cases are still in development:
- MLJ's TunedModel workflow integration
- MLJ's IteratedModel workflow integration
Achievements and acknowledgments
For me, the most important achievement was learning about how to contribute to the open source community. I'm feeling grateful for that because it was a new adventure for my professional development. It's a fact that this opportunity is going to improve the way I think about how to implement a project. As a contributor from now on, I am quite enthusiastic to be able to cooperate with the MLJ project, to the point of being able to apply it within my professional and academic circle not only as a user, but also as an ambassador.
I'm completely grateful with my mentors, Antony and Deyan, who had the patience to help me with my questions; giving me a piece of their time. I'll never forget it.

Top comments (0)