Recently I went to profile a short-running function. Several Julia packages, ProfileCanvas.jl being one of them, provide functionality for getting a CPU execution profile, often via a macro called like @profview expr_to_profile.
One problem that can occur is the run time of one invocation of expr_to_profile being so short that the profile ends up being useless because not enough samples are collected. Here's a quick-and-dirty hack solution to this problem. Criticize it in the comments below!
Example: profiling cos(::Float64)
"""
run_in_a_loop(run_workload, get_argument, repeat_count)::Nothing
"""
function run_in_a_loop(run_workload::F, get_argument::G, repeat_count::Int) where {F, G}
for i ∈ 1:repeat_count
x = get_argument(i)
r = @noinline run_workload(x)
Base.donotdelete(r)
end
end
# Example: profile `cos(::Float64)` execution
# Use a global to prevent constant folding, but precompute everything
# to allow the intended workload to dominate the profiling results.
precomputed_arguments::NTuple{128, Float64} = (rand(Float64, 128)...,);
function get_argument(i::Int)
axs = Base.OneTo(length(precomputed_arguments))
j = mod(i, axs)
precomputed_arguments[j]
end
# Use a global to prevent unexpected compiler optimization.
repeat_count::Int = 1000000
using ProfileCanvas: @profview
# Get everything compiled. The profile may (?) include compilation
# here, so we're not interested in it yet.
run_in_a_loop(cos, get_argument, repeat_count)
@profview run_in_a_loop(cos, get_argument, repeat_count)
# Run again to see run-time performance.
repeat_count *= 1000
@profview run_in_a_loop(cos, get_argument, repeat_count)
Here's the profile flame graph I ended up with:
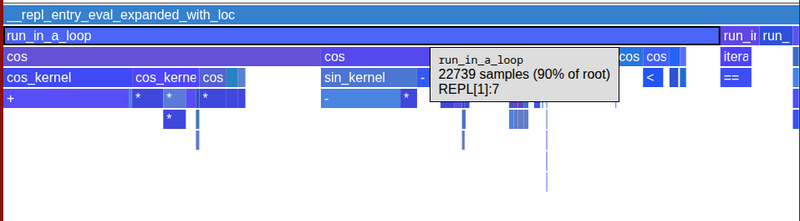
So about 85% of the samples do end up in cos, even though a single call of cos(::Float64) is over very quickly. Not bad!
donotdelete
The secret sauce above is donotdelete. This is its doc string:
help?> Base.donotdelete
│ Warning
│
│ The following bindings may be internal; they may change or be removed in future versions:
│
│ • Base.donotdelete
Base.donotdelete(args...)
This function prevents dead-code elimination (DCE) of itself and any arguments passed to it, but is
otherwise the lightest barrier possible. In particular, it is not a GC safepoint, does not model an
observable heap effect, does not expand to any code itself and may be re-ordered with respect to
other side effects (though the total number of executions may not change).
A useful model for this function is that it hashes all memory reachable from args and escapes this
information through some observable side-channel that does not otherwise impact program behavior. Of
course that's just a model. The function does nothing and returns nothing.
This is intended for use in benchmarks that want to guarantee that args are actually computed.
(Otherwise DCE may see that the result of the benchmark is unused and delete the entire benchmark
code).
│ Note
│
│ donotdelete does not affect constant folding. For example, in donotdelete(1+1), no add
│ instruction needs to be executed at runtime and the code is semantically equivalent to
│ donotdelete(2).
│ Note
│
│ This intrinsic does not affect the semantics of code that is dead because it is
│ unreachable. For example, the body of the function f(x) = false && donotdelete(x) may be
│ deleted in its entirety. The semantics of this intrinsic only guarantee that if the
│ intrinsic is semantically executed, then there is some program state at which the value of
│ the arguments of this intrinsic were available (in a register, in memory, etc.).
│ Julia 1.8
│
│ This method was added in Julia 1.8.
Examples
≡≡≡≡≡≡≡≡
function loop()
for i = 1:1000
# The compiler must guarantee that there are 1000 program points (in the correct
# order) at which the value of `i` is in a register, but has otherwise
# total control over the program.
donotdelete(i)
end
end
Similar functionality in Rust:
Some C++ libraries offer similar functionality, too. For example, the folly library has doNotOptimizeAway.
EDIT: Base.donotdelete is now a public interface:

Top comments (0)