Disclaimer: This is an unreleased draft: the wording is sloppy and there are points I don't build on enough or have nothing new to say about. I'm working on an updated version, but as it focuses purely on a subset of these points I felt it useful to "release" this to those interested.
As a relatively young language, many useful resources exist for learning to optimise Julia code, but they are hard to find without digging in a variety of places. C++, on the other hand, has been used for decades in performance critical applications such as high-frequency trading or computer graphics. Collated advice for writing generic, turbo C++ code is now so easy to access, that I accidentally stumbled upon Chris Wyman's concisely written Tips for Optimizing C/C++ Code while looking for resources about Julia. In this article I will analyse how the advice, originally written for C++03, can be applied to helping Julia code achieve the speed it deserves.
Practical Advice
Some of the tips are entirely language and architecture agnostic, simply being good practice for maximising the efficiency of your efforts. The first of these is Ahmdal's Law:
Put simply, don't waste time on optimising pieces of code that don't have a large impact on the overall run-time. Instead, as the second tip states, "code for correctness first, then optimize". It will be sooner rather than later that going against this advice will sting you majorly. Especially in dynamic languages like Julia which have a tendency to fail silently, just because something runs doesn't mean it is correct. Additionally, once correct code is written, the most obvious optimisations should be applied first. In Julia, this covers things like checking for global variables, type stability more generally, and lowering the number and size of allocations.
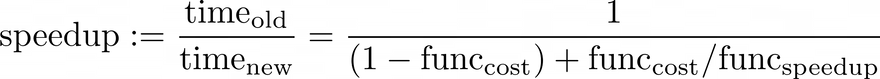
However, before even writing code one should consider whether the mathematics itself can be simplified. There may be theorems that apply in specific cases that can vastly improve performance. An example of this would be taking a moment to apply conjugacy laws when performing Bayesian modelling where simulations could be unnecessary due to the existence of closed form solutions.
We can summarise this section with Chris' own words:
"People I know who write very efficient code say they spend at least twice as long optimizing code as they spend writing code."
"Jumps/branches are expensive. Minimize their use whenever possible."
The overhead of a function call in C++ and Julia is nontrivial. As
written originally by Chris, a function call requires two jumps and some stack memory manipulation. Hence, iteration is preferred to recursion, functions should preferably be outside long loops, and you should test
whether functions are being inlined by the compiler. In Julia, however, since dynamic dispatch is performed on the arguments of each function call, you could actually make your code far less efficient by removing function calls which would deny the compiler the chance to specialise the code. In most cases (and as will become a theme in this article), trying to do the compiler's job will not be worth the effort, but there may be times where the types you're dealing with are homogeneous, and the code is not expected to be generic, modular, or particularly nice to read.
The code below is an admittedly specific example of such a situation. Personally, I find the former two methods easier to read, but limiting the number of function calls does indeed increase performance.
using BenchmarkTools
@inline f_inline(v, i) = sqrt(1 + sum(v) * i)
@noinline f_noinline(v, i) = sqrt(1 + sum(v) * i)
function f_loopinside(v)
for i in eachindex(v)
v[i] = sqrt(1 + sum(v) * i)
end
return nothing
end
function run_inline(v)
for i in eachindex(v)
v[i] = f_inline(v, i)
end
return nothing
end
function run_noinline(v)
for i in eachindex(v)
v[i] = f_noinline(v, i)
end
return nothing
end
function run_loopinside(v)
f_loopinside(v)
return nothing
end
@benchmark run_inline(v) setup = (v = zeros(10_000)) # 13.133 ms
@benchmark run_noinline(v) setup = (v = zeros(10_000)) # 13.493 ms
@benchmark run_loopinside(v) setup = (v = zeros(10_000)) # 12.694 ms
Another piece of advice given in Chris' article is the use of switch statements to replace long if-elseif chains as these also require jumps, whereas a switch can be optimised into a table lookup with a single jump. I have only been able to generate switch statements in very specific situations where the cases and results are constant tuples of integers, and the cases are matched with equality.
"Think about the order of array indices."
C++ is a row-major language, meaning A[i,j] is next to A[i,j+1] but may be arbitrarily far away from A[i+1,j] as arrays are stored as rows in memory. In Julia, the opposite is true as, along with many other scientific languages such as Fortran, MATLAB, and R, it is a column-major language. Following these data locality guidelines helps performance because data is loaded from memory into the register in chunks as opposed to single value addresses. Hence, in Julia, fetching A[i,j] means A[i+1,j] will already be in the register, but A[i,j+1] will need to be fetched from cache (and needing to do so would be called a cache miss).
“Think about instruction-level-parallelism.”
To take advantage of the fact that CPUs can do many instructions at once, we need to make sure that we’re giving it enough independent pieces of computation to do. This is most often accomplished by loop-unrolling, where, for example, instead of incrementing an iterator by 1 and performing a single instruction, you increment the iterator by 4 and give the CPU 4 instructions in a single iteration of the loop. C++ compilers are given static code which is easy to reason about and hence can determine the speed/binary size trade-off of loop-unrolling. The Julia compiler, on the other hand, will try its best to vectorise the inherently dynamic code it’s given, but may need assurance through the use of the macros @inbounds, @simd, @simd ivdep to determine whether certain properties of the code will hold.
“Avoid/reduce the number of local variables.”
The reason Chris gives for this tip is that in C++, if there are few enough local variables then they don’t need to be stored on the stack and can be directly stored in the registers, avoiding the need to set up and destroy a stackframe and allowing for faster memory access. In the past, the use of the register keyword in C++ was a way of hinting that a certain variable would be used often and it would be a good candidate for the compiler to determine to store in the register. However, this keyword was deprecated in C++11 as modern compilers are much better at this sort of optimisation.
In Julia, there has never been a way to explicitly put variables in the register but the idea that there exists something “faster than the stack” that we should aim to help the compiler utilise is true for Julia as well. Users should ensure that as many as possible of their small variables can be stack allocated. In some cases, short-lived variables that would have been stack allocated will be optimised away entirely, and even if not, stack allocated variables are far easier for the compiler to reason about (otherwise they wouldn’t be on the stack). The use of StaticArrays is commonly recommended for small to medium sized arrays of less than 100 elements in order to speed up small matrix operations.
“Pass structures by reference, not by value.”
In high level languages, variables have three fundamental attributes: what they contain, what they are called, and where they are stored. There are various things that could happen when a variable is passed to a function as one of its arguments. If it is passed by reference, the function is given the variable’s location in memory, and its value, possibly assigning it a new temporary label. In this case, if the function changes the value associated with this new label, then once the function terminates and the variable regains its original label, the changes made will be permanent. If we instead pass the variable by value, the function is given a copy of the original but with a different memory address and a temporary label, hence any changes made to the argument are entirely temporary as the function has no access to the original variable. Given that making a copy takes time and memory, passing by reference is preferred when speed is important.
Julia does things a bit differently. Put simply, the argument and its temporary label will refer to the original variable and its location in memory as long as the label is not assigned a new object. At that point, the label switches to referring to the location in memory of this new object and the original variable will be unaffected by future changes. This is sometimes called pass-by-sharing.
mutable struct Thing
x
end
t = Thing(10)
@show t.x # prints t.x = 10
function change_argument(thing)
thing.x += 1
return nothing
end
change_argument(t)
@show t.x # prints t.x = 11
function change_object(thing)
thing = Thing(thing.x+1)
return nothing
end
change_object(t)
@show t.x; # prints t.x = 11 NOT t.x = 12
Given that the programmer has no choice in Julia, the tip no longer applies, but knowing about how this particular aspect of the language works is important to not be caught out when dealing with mutable objects such as arrays.
“If you do not need a return value from a function, do not define one.”
Returning nothing in Julia is recommended when a return value is not necessary (for example, when the function just mutates its arguments). It is mostly for code clarity and is a simple way to ensure type stability of the output. It is merely a convention and won’t do anything magical to speed up mutating functions.
“Try to avoid casting where possible.”
Changing the datatype of a variable may require a copy from one register to another, as each register can only perform instructions on certain datatypes. The most common example is integer and float conversion.
“The difference between math on integers, fixed points, 32-bit floats, and 64-bit doubles is not as big as you might think.”
On x86 hardware, you can read/write to the first one, two, four or eight bits of an integer register at once, but in every case the whole register is used, no matter the size of the input. The implication of this is that 8/16/32-bit integers are essentially converted to and from 64-bits before and after being operated on respectively, meaning while they save on memory, they won’t necessarily save on execution time.
However, since the writing of Chris’ original article, 256 or even 512-bit AVX (advanced vector extension) aka SIMD (single instruction, multiple data) registers have become commonplace. These AVX registers can perform as many instructions at once as values can fit inside them, hence vectorised code can have a huge performance boost from switching to 32-bit or smaller integers and floats. For this reason, certain domains such as deep learning make extensive use of lower-precision datatypes in order to take better advantage of SIMD instructions.
One very important caveat is that modern CPUs don’t actually support Float16 operations, and so performing a Float16 operation involves converting to and from Float32. This makes CPU Float16 operations painfully slow, which can be seen in the code example below where we compare summing 64, 32, and 16-bit Floats with and without SIMD.
using BenchmarkTools
function mysum(v::Vector{T}) where {T}
t = T(0)
for x in v
t += x
end
return t
end
function mysum_simd(v::Vector{T}) where {T}
t = T(0)
@simd for x in v
t += x
end
return t
end
function bench()
myvector = collect(1.0:1.0:1000.0)
b1 = @benchmark mysum($myvector)
b1_simd = @benchmark mysum_simd($myvector)
myf32vector = Float32.(myvector)
b2 = @benchmark mysum($myf32vector)
b2_simd = @benchmark mysum_simd($myf32vector)
myf16vector = Float16.(myvector)
b3 = @benchmark mysum($myf16vector)
b3_simd = @benchmark mysum_simd($myf16vector)
b1, b1_simd, b2, b2_simd, b3, b3_simd
end
# Run benchmarks
benchmark_res = bench()
## Float64
benchmark_res[1] # without SIMD: 1.110 μs
benchmark_res[2] # with SIMD: 79.835 ns
## Float32
benchmark_res[3] # without SIMD: 1.180 μs
benchmark_res[4] # with SIMD: 43.895 ns
## Float16
benchmark_res[5] # without SIMD: 6.717 μs
benchmark_res[6] # with SIMD: 6.733 μs
“Be very careful when declaring C++ object variables.”
Chris points out that Color c(black); is faster than Color c; c = black;. The same is true in Julia and given that structs are immutable by default, the latter is at least somewhat discouraged by design.
“Make default class constructors as lightweight as possible.”
This is good advice for both languages: given that constructors are called often, sometimes without the programmer realising, they should be made as efficient as possible.
“Use shift operations instead of integer multiplication and division, where possible.”
While it can be hard to compare the speed of these operations due to how little time they take, with modern compilers it’s generally best to just tell the compiler what you want to happen and let it decide the best way to perform these operations given the available information. In Julia this makes type stability even more important: a certain operation may be able to be simplified, but only if certain type requirements are met.
“Be careful using table-lookup functions”
TODO: SAY MORE ABOUT THIS.
Chris states that, while precomputed value lookups are encouraged by many, the memory lookup is often more expensive than just recomputing the value. This is just a general piece of programming advice but applies more to fast languages than slower ones.
“For most classes, use the operators +=, -=, `=, and /= , instead of the operators +, -, , and /` .”
Chris notes that in C++, the code
Vector v = Vector(1,0,0) + Vector(0,1,0) + Vector(0,0,1);
allocates the final object v, as well as temporary object variables Vector(1,0,0), Vector(0,1,0), Vector(0,0,1), and the results of the intermediate operations Vector(1,0,0) + Vector(0,1,0) and Vector(1,1,0) + Vector(0,0,1). This makes five temporary allocations in total. We can improve this by instead writing the code
Vector v(1,0,0);
v += Vector(0,1,0);
v += Vector(0,0,1);
which doesn’t need to allocate any temporary vectors for intermediate results and allocates the first intermediate variable as the final result, thereby reducing the total number of temporary allocations (and therefore calls to the constructor and destructor) to just two.
In Julia, defining Vector as a three-argument mutable struct and running the equivalent code produces different internal representations through @code_lowered, but as soon as type inference kicks in, the generic instructions are replaced with their actual implementations and both ways of adding three vectors become equivalent. In fact, both versions of the function only perform a single allocation as the temporary objects are known not to escape the function’s local scope.
import Base.+
mutable struct vec3{T}
x::T
y::T
z::T
end
(+)(a::vec3, b::vec3) = vec3(a.x + b.x, a.y + b.y, a.z + b.z)
add_ooplace() = vec3(1, 0, 0) + vec3(0, 1, 0) + vec3(0, 0, 1)
function add_inplace()
b = vec3(1, 0, 0)
b += vec3(0, 1, 0)
b += vec3(0, 0, 1)
end
@time add_inplace() # (1 allocation: 32 bytes)
@time add_ooplace() # (1 allocation: 32 bytes)
It can be tough to know exactly what the Julia compiler will or won't do, especially when working with more complicated structs. It could be that certain variables are constant-folded/propagated while others are stack-allocated and others are heap allocated. It is important to understand the guarantees you can offer the compiler and its capabilities given this information. In the somewhat trivial example above, we guaranteed that the (temporary) objects wouldn't escape, and so the compiler elided their allocation entirely.
“Delay declaring local variables.”
The original tip states that one should put variable declarations inside if-statements if the variable is only needed for that branch. This is done to avoid calls to the constructor. As above, however, the Julia compiler should be able to determine whether the allocation is necessary when the code is type stable:
# Using vec3 struct defined in previous tip
declare_inside(v1::vec3) = v1.x > 2 ? v1 + vec3(1, 2, 3) : v1
function declare_outside(v1::vec3)
v2 = vec3(1, 2, 3)
v1.x > 2 ? v1 + v2 : v1
end
# Interpolation with $() to avoid initial allocation of v1
@benchmark declare_inside($(vec3(1, 1, 1))) # 0 allocations
@benchmark declare_outside($(vec3(1, 1, 1))) # 0 allocations
“For objects, use the prefix operator (++obj) instead of the postfix operator (obj++).”
In C++, the postfix operator makes a copy of the object; the prefix operator does not. In Julia, neither of the two operators are defined and if one were to define an operator with increment functionality, one should make sure that no copies are made.
“Be careful using templates.”
A template in C++ defines a family of types or functions, the Julia
quasi-equivalents would be parametric types and generated functions. The
spirit of the original question is less warning against using templates,
and more about using templates defined by other programmers such as
those from the Standard Template Library (STL). Chris argues that, by
using the STL, you know less about the implementation of the templates
than if you had written them by hand. For example, the default sorting
algorithm for a certain type could be improved upon in your particular
use case due to some invariants.
In Julia, I would turn this around entirely and strongly encourage the
use of the types defined in others’ packages[1]. The Julia ecosystem is
supposed to be all about composability, so if there exists a predefined
type in some package offering similar functionality to your work, then
utilising it in your work would mean that the users of this package
could immediately make use of your work. Perhaps they could even embed
it in their own work provided that they also utilised the same type.
Additionally, it is fairly likely that actively maintained packages for
common functionality, especially those used in other packages such as
finite differences to calculate gradients, are more robust than the
implementation a single programmer requiring the functionality could
quickly muster up.
[1] And when it doesn’t work, please write detailed blog posts
complaining about certain things not working. People have started doing
this recently and it’s done wonders for serious discussion on the new
user experience, as well as guides for making libraries more composable.
“Avoid dynamic memory allocation during computation.”
This is common advice for newer Julia programmers and was touched upon
earlier in the tip about avoiding local variables. In short, dynamic
memory is slow because the addresses are not statically known to the
compiler because objects can change. Large objects such as large arrays
aren’t so much of an issue because they are guaranteed to be large
contiguous blocks of memory and so retain one of the stack’s benefits,
but when there are many smaller objects allocated and destroyed quickly,
such as in vector operations, the overhead incurred by dynamic memory
allocation is a strong candidate to be looked at for code optimisation.
StaticArrays.jl is commonly used in these cases.
“Find and utilize information about your system’s memory cache.”
Chris advises that certain structs can be designed to fit into a single
cache line, and so only require a single fetch from main memory to be
entirely retrieved. Julia programmers can also take advantage of this by
using the sizeof and Base.summarysize functions to determine how
large a struct and its arguments are respectively.
“Avoid unnecessary data initialization.”
When memory is allocated, certain bytes are designated to hold the value
of a certain object. Initialisation is the act of changing that memory
to a certain value once it has been allocated. When one doesn’t need the
initial value of the allocated memory to be defined, such as when it
will be overwritten later in its life without ever referring to itself,
then there is no need to spend the time initialising the value.
Chris advises the consideration of the C function memset, an
incredibly fast and loose way of setting chunks of memory to a certain
value. The equivalent function in Julia, fill! not only exists, but
directly calls memset. For allocation without initialisation, the
undef value can be used in Julia e.g. ArrayT(undef, dims).
Acknowledgements
Thank you to Gabriel Baraldi, Henrique Becker, Mosè Giordano, Stephan Kleinbölting, Mark Kittisopikul, Sukera, Chris Elrod, Frames Catherine White, Valentin Churavy, and Leandro Martínez for their contributions to the original thread and answering my Slack questions :)

Top comments (0)